Vevo2: A Unified and Controllable Framework for Speech and Singing Voice Generation
Abstract
Controllable human voice generation, particularly for expressive domains like singing, remains a significant challenge. This paper introduces Vevo2, a unified framework for controllable speech and singing voice generation. To tackle issues like the scarcity of annotated singing data and to enable flexible controllability, Vevo2 introduces two audio tokenizers: (1) a unified music-notation-free prosody tokenizer that captures prosody and melody from speech, singing, and even instrumental sounds, and (2) a unified content-style tokenizer that encodes linguistic content, prosody, and style for both speech and singing, while enabling timbre disentanglement. Vevo2 consists of an auto-regressive content-style modeling stage, which aims to enable controllability over text, prosody, and style, as well as a flow-matching acoustic modeling stage that allows for timbre control. Particularly, during the speech-singing joint training of the AR model, we propose both explicit and implicit prosody learning strategies to bridge speech and singing voice. Moreover, to further enhance the Vevo2’s ability to follow text and prosody, we design a multi-objective post-training task that integrates both intelligibility and prosody similarity alignment. Experimental results show that the unified modeling in Vevo2 brings mutual benefits to both speech and singing voice generation. Additionally, Vevo2’s effectiveness across a wide range of synthesis, conversion, and editing tasks for both speech and singing further demonstrates its strong generalization ability and versatility.
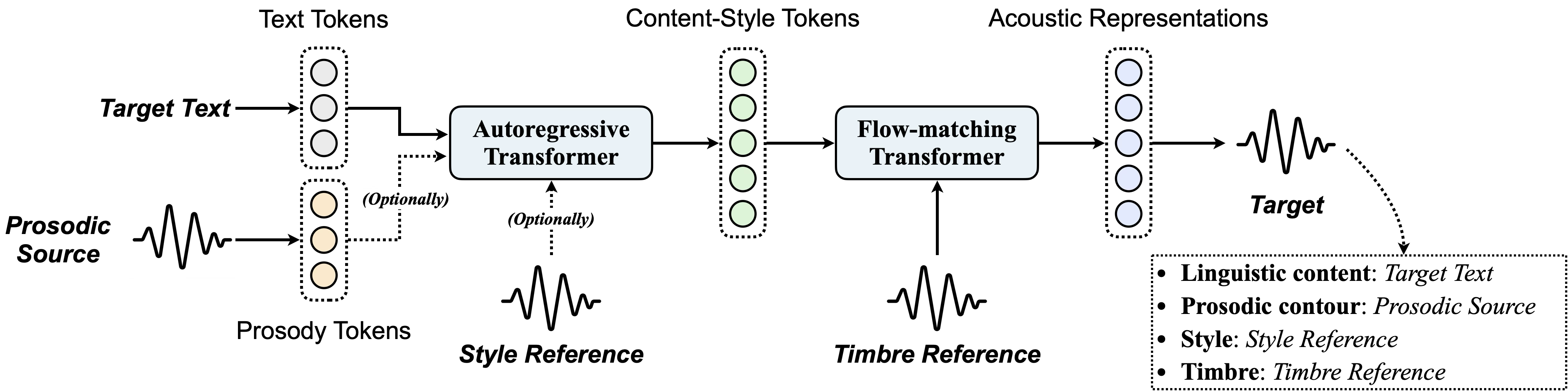
What can Vevo2 do?
Vevo2 is a versatile and controllable voice generation framework designed to unify speech and singing voice. It consists of an auto-regressive (AR) content-style modeling stage, which aims to enable controllability over text, prosody, and style, as well as a flow-matching (FM) acoustic modeling stage that allows for timbre control. It is able to support versatile synthesis, conversion, and editing tasks through a unified inference pipeline.
Extend Zero-Shot TTS to Singing Voice Domain
Under the standard zero-shot text-to-speech (TTS) inference pipeline, Vevo2 extends its support beyond speech data to include singing voice data as reference prompts, which we define as the text-to-singing task. Notably, even without explicit prosodic contour control (i.e., without using a prosodic source), the synthesized output could follow and extend the reference's melodic pattern, demonstrating melody imitation or continuation.
| Task | Target Text | Style Reference | Timbre Reference | Results |
|---|---|---|---|---|
| Text to Speech | In just a heartbeat, I can traverse oceans, cross mountains, and explore cities that I've only dreamed of. | |||
| I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring. Respect me and I'll nurture you; ignore me and you shall face the consequences. | Hindi-accented, Male | Mandarin, Female | Hindi-accented, Female | |
| Text to Singing | Don't forget me, I'm calling your name. I remember you said, love's not always the same. | Adele (British singer) | ||
| 我皱着眉头,感受着那份压力,但我知道我不能放弃,不能认输。于是,我深吸一口气,心底的声音告诉我 | 周杰伦 (Chinese singer) | 太乙真人 (Chinese animated character) |
When feeding this generated result into an external singing-to-song system: |
|
Note: The prosodic source is not used during the inference.
Versatile Melody Controls for Singing Voice Generation
Vevo2 provides supports for using an explicit prosodic source to control the prosody/melody of the synthesized output. Particularly, it accommodates various forms of prosodic sources, including general speech and singing voice (as demonstrated in the subsequent section of editing tasks), whistle sounds (the first case of the following table), humming voices (the second case), and even instrumental musical sounds (the last two cases).
| Task | Target Text | Prosodic Source | Style Reference | Timbre Reference | Results |
|---|---|---|---|---|---|
| Humming to Singing | Moonlight dancing through the starry sky. Snowflakes falling in the winter night. |
Whistle sound
(Melody: the theme song of A Fistful of Dollars) |
Adele (British singer) | ||
| 你是我的小呀小苹果,怎么爱,不嫌多 |
Humming sound
(Melody: Beethoven - Für Elise) |
太乙真人 (Chinese animated character) | |||
| Instrument to Singing | It's always just me facing the sky, my mind roaming freely like the clouds. |
Piano sound (rendered from MIDI)
(Melody: 罗大佑 - 童年) |
Adele (British singer) | ||
| 朝霞染红天际,暖阳依旧,新希望 |
Trumpet sound (real recordings)
(Melody: Joe Hisaishi - The Sun Also Rises) |
孙燕姿 (Chinese singer) | |||
Note: To accommodate melody control through MIDI score (a standard approach in the conventional SVS task), we can render MIDI as instrumental sound to facilitate inference (as demonstrated in the third case of the table).
Prosody-preserved Speech and Singing Lyric Editing
For editing tasks, Vevo2 not only demonstrates superior performance in synthesized audio naturalness but also effectively preserves the original prosody and melody. For instance, in singing lyric editing tasks (the last four cases of the following table), Vevo2 enables selective modification of lyrics while maintaining the original melodic contour of the singing voice.
| Task | Raw Audio | Raw Text | Target Text | Results |
|---|---|---|---|---|
| Speech Editing | Who would've imagined that people could really turn into water... | Who would've imagined that people could truly turn into fire... | ||
| 没什么是一发利箭不能解决的。如果有,那就两发。 | 没什么是两发利箭可以解决的。如果有,那就五发。 | |||
| Singing Lyric Editing | Adele (British singer) | Never mind, I'll find someone like you. I wish nothing but | Never mind, you'll find anyone like me. You wish nothing but | |
| Never mind, I'll find someone like you. I wish nothing but | Alright, I'll turn over a new page. I wish for calm | |||
| 周杰伦 (Chinese singer) | 对这个世界如果你有太多的抱怨,跌倒了就不该继续往前走,为什么,人要这么的脆弱堕 | 对你的人生如果你有太多的期盼,跌倒了就不该低头认输,为什么,人要这么的彷徨堕 | ||
| 对这个世界如果你有太多的抱怨,跌倒了就不该继续往前走,为什么,人要这么的脆弱堕 | 对强化学习如果实验遇到了瓶颈,损失值就不该太大动荡,看梯度啊,网络何时被优化好 |
Note: In the editing tasks, the raw audio serves simultaneously as the prosodic source, style reference, and timbre reference during inference.
Unified Zero-Shot VC and SVC
To conduct voice conversion (VC) or singing voice conversion (SVC) tasks, Vevo2 exhibits two distinctive characteristics. First, Vevo2 uses a unified content-style tokenizer both speech and singing voice domains. Second, Vevo2 supports both style-preserved and style-converted conversion tasks:
- When using only the FM stage, i.e., without using the style reference (just as the first and the third cases of the following table), Vevo2 can only convert the timbre but preserve the style of the source audio.
- When using both the AR and the FM stages, Vevo2 can convert both the timbre and the style of the source audio, resulting in higher similarity to the target speaker(singer).
| Task | Source Audio | Style Reference | Timbre Reference | Results |
|---|---|---|---|---|
| Voice Conversion | American-accented, Female | / | Hindi-accented, Male | American-accented, Male |
| Hindi-accented, Male | Hindi-accented, Male | |||
| Singing Voice Conversion | Michael Jackson (American singer) | / | Adele (British singer) | More head resonance |
| Adele (British singer) | More chest resonance |
Note: In the VC task, the prosodic source is not used during the inference. In the SVC task, we use source audio as the prosodic source.
Versatile Speech and Singing Style Conversions
Vevo2 enables versatile speech and singing style conversion tasks. Specifically, the system can utilize different style references (such as different accents, emotions, singing techniques, etc.) to transform the source audio's style, while preserving its original timbre by using itself as the timbre reference:
| Task | Source Audio | Style Reference | Results |
|---|---|---|---|
| Accent Conversion | American-accented, Female | Hindi-accented, Male | Hindi-accented, Female |
| Emotion Conversion | Emotional, Male | Emotional, Female | |
| Whisper-to-Normal Conversion | Whisper | Normal | Normal |
| Singing Style Conversion | Normal, Male | Extensive vibratos and tempo rubato, Female | More Vibratos, Male |
| 陶喆 (Chinese singer) | More Vibratos, Tempo rubato | ||
| More Vibratos, Tempo rubato |
Note: The source audio serves as the timbre reference in these conversion tasks. On the speech domain (such as the first three cases), the prosodic source is not used. On the singing domain (such as the last three case), the source audio also serves as the prosodic source.